
-1.png)
1. はじめに
CPU使用率は高くないのに応答が遅い—そんなときに多いのが I/O待ちです。
この記事では、I/Oがボトルネックになったケースを例に、どの数字を、どの順番で見れば原因を絞り込めるかをまとめます。
2. この章で使う用語
- iowait(%wa)
CPUがI/Oの完了待ちで止まっている割合。高いほど「CPUは空いているのに処理が進まない」=ディスク側の影響が疑われる。 - %util(ディスク利用率)
ディスクが処理に張り付いている時間の割合。80〜100%に張り付くとディスクが混んでいるサイン。 - await(平均待ち時間)
I/O 1件あたりの平均待ち時間(キュー待ち+処理)。平常時の2〜3倍以上に伸びていれば待ちが顕在化。 - avgqu-sz(平均キュー長)
ディスクのI/O行列の長さ。増えていれば行列が伸びており、ほかの指標(%util・await)と同時に悪化していないかを見る。 - run queue(ランキュー)
CPUで実行開始を待つタスクの本数。コア数を長く超える状態が続けば、CPUの処理が追いついていない可能性が高い(I/Oが原因のときはここが大きくなりにくい)。 - ワークロード(workload)
実行する処理の中身と量(リクエストの種類・同時数・データ量・アクセスパターン)
3. ケース概要(I/Oがボトルネックになった例)
※以下は一般的な目安 です。
OS/ホスト視点
- iowait(%wa):ピーク帯で 10〜30%超が継続
- CPU使用率:50〜70%程度(張り付きではない)
- run queue:コア数以下(CPU渋滞は小さい)
ディスク視点(iostat -x など)
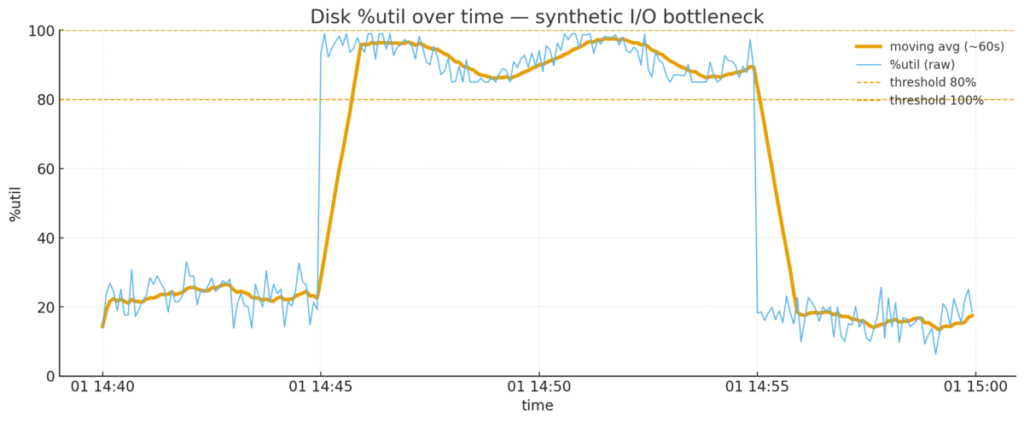
- %util:80〜100%で張り付き
- await:普段の2〜3倍以上
- avgqu-sz:明らかに増加(行列が伸びている)
- rkB/s, wkB/s:ピーク時に大きな山
アプリ/DB視点
- 時間のかかるSQLが増える/DBからの読み取りが多い
- ログ出力や一時ファイル書き込みが同時に増える
→ CPUに余力はあるが、ディスクの完了待ちが長く行列が伸びている構図。
の推移-1024x422.png)
4. 見方の手順
- iowait(%wa)を見る
10〜30%以上が続くなら、主な理由は CPU ではなくディスク待ちの可能性が高い。 - ディスクの混み具合を確認する(iostat -x)
%util が 80〜100%で続き、await が普段の数倍、avgqu-sz が増えているなら、ディスク側で詰まっていると考えられる。 - CPU側に余力があるかも合わせて見る
CPU使用率が張り付きではなく、実行待ち(run queue)がコア数を大きく超えていないなら、原因はCPU不足ではないと判断できる。 - I/Oを増やしている原因を見つける
時間のかかるSQL、DBからの読み取りの増加、ログや一時ファイルの書き込み増など、どれが効いているかを確かめる。
5. 観測チェック項目
- [ ] iowait(%wa) が 10〜30%以上の状態が続いている
- [ ] iostat -x で %util が 80〜100%/await が普段より大きい/avgqu-sz が増えている
- [ ] CPU 使用率は 50〜70% 程度で、実行待ち(run queue)がコア数を大きく超えていない
- [ ] 時間のかかる SQL、DB からの読み取り増、ログ/一時ファイルの書き込み増の有無を確認
6. 具体的な目安(参考)
| 指標 | 目安 | 見方 |
|---|---|---|
| iowait(%wa) | 10〜30%以上が継続 | ディスク待ちの可能性が高い |
| %util | 80〜100%に張り付き | ディスクが混んでいるサイン |
| await | 普段の2〜3倍以上 | 待ち時間が伸びている |
| avgqu-sz | 明らかに増加 | 行列が伸びている |
※表の数値はワークロード依存です。リクエスト種別・同時数・データ量が異なれば閾値も動きます。
7. まとめ
I/Oの詰まりを見抜くコツは次のとおりです。
- 全体像:CPUには余力があり、run queue も小さい。一方で iowait が高く、%util・await・avgqu-sz がそろって悪化している。
- 読み取り:主因はディスクの完了待ち(混雑で行列が伸びている)。
- 確認の流れ:iowait の上昇 → ディスク指標(%util・await・avgqu-sz)の悪化 → CPU使用率と run queue で裏取り → I/O増の要因を特定。
- 次の一歩:どの処理が I/O を増やしているかを計測で特定する。
-1.png)
コメント