Zabbixとは
Zabbixはインフラの健全性を継続的に確認するための監視ツールです。性能テストや本番運用におけるボトルネックの特定、障害の予兆検知といった場面で、監視データは非常に役立ちます。
本記事では、アプリケーションサーバー(AP)とデータベースサーバー(DB)に分けて、Linuxサーバーで監視すべき主要な項目と、性能問題の兆候をどのように捉えるかを解説します。
項目一覧(APサーバー)
| 項目名 | 種別 | 説明 |
|---|
| CPU load | CPU | ロードアベレージ(1分/5分/15分)。高いとプロセス待ちの可能性あり。 |
| CPU utilization | CPU | CPU利用内訳(ユーザー、システム、アイドル)。 |
| CPU jumps | CPU | CPU負荷の急上昇を検知。スパイク監視に有効。 |
| Apache Idle/Busy | CPU / アプリ | Apacheのアイドル/ビジー状態。Webサーバーの負荷状況。 |
| Disk I/O on /dev/mapper/vg1-root | ディスク | ルートパーティションのI/O。読み書き負荷の確認。 |
| Disk I/O on /dev/mapper/vg1-swap | ディスク | スワップ領域のディスクI/O。頻繁ならメモリ不足の兆候。 |
| Disk I/O on /dev/sda2 | ディスク | /dev/sda2 のディスクI/O量。全体の負荷状況の把握に。 |
| Disk space usage / | ディスク | ルートパーティションの空き容量。容量逼迫の検知に重要。 |
| Disk space usage /boot | ディスク | /boot領域の空き容量。カーネル更新に影響あり。 |
| Memory usage | メモリ | 使用中・空き・キャッシュ状況。メモリリークや不足の兆候。 |
| Swap usage | メモリ | スワップ使用率。スワップ多発=物理メモリ不足の可能性。 |
| Network traffic on bond0 | ネットワーク | bond(複数NICを束ねた)インタフェースの通信量。 |
| Network traffic on eth0 | ネットワーク | eth0インタフェースの送受信量。 |
| HTTP Process | アプリ | Webアプリのプロセス数や状態。過負荷や死活の確認。 |
| mailqueue | アプリ | メールキューの溜まり具合。配信遅延や障害の兆候。 |
| healthCheck | アプリ | 任意のヘルスチェック結果。アプリの健全性確認に。 |
項目一覧(DBサーバー)
| 項目名 | 種別 | 説明 |
|---|
| CPU load | CPU | システムの平均負荷(ロードアベレージ)。高いと処理待ちのプロセスが多い。 |
| CPU utilization | CPU | ユーザー処理/システム処理/アイドル時間の割合。CPUの使用効率を把握。 |
| CPU jumps | CPU | 瞬間的なCPU使用率のスパイクを検知。急激な負荷変化の監視に。 |
| Disk I/O on /dev/mapper/vg1-root | ディスク | ルートボリュームのI/O。DBファイル格納先ではないことも。 |
| Disk I/O on /dev/mapper/vg1-swap | ディスク | スワップ領域のディスクI/O。スワップ多発はメモリ不足のサイン。 |
| Disk I/O on /dev/sda2 | ディスク | /dev/sda2 へのI/O。DBがここにある場合、負荷の主要指標。 |
| Disk space usage / | ディスク | ルートパーティションのディスク使用率。 |
| Disk space usage /boot | ディスク | /bootの空き容量。通常は更新時以外は変化少。 |
| Memory usage | メモリ | メモリの使用状況。DBバッファやキャッシュも含め確認できる。 |
| Swap usage | メモリ | スワップ使用率。大量使用時はメモリ設計の見直しが必要。 |
| Network traffic on bond0 | ネットワーク | bondインターフェース(冗長化されたNIC)の送受信トラフィック。 |
| Network traffic on eth0 | ネットワーク | eth0インタフェースの通信量。DB接続やレプリケーション等の把握に有効。 |
| healthCheck | アプリ | DBの死活監視などに利用されるヘルスチェック結果。 |
APサーバーで重視すべき項目と見るべき観点
| 項目名 | 評価観点 | 説明 |
|---|
| CPU load / CPU utilization | 高負荷検出 | 同時リクエスト数が多いと上昇。処理能力限界の把握に重要。 |
| Memory usage | メモリ使用量の妥当性 | Javaアプリなどでヒープ領域が逼迫していないかを確認。 |
| Swap usage | メモリ不足の兆候 | スワップに頼っていると性能劣化の原因。使用率があるとNG。 |
| Disk I/O(root, swap, sda2) | ログ出力・キャッシュなどの書き込み負荷 | アクセスログや一時ファイルでI/Oが増加することも。 |
| Network traffic(bond0, eth0) | クライアント⇔APの通信量 | リクエスト数・レスポンス量が多いとネットワークボトルネックに。 |
| HTTP Process / Apache Idle/Busy | アプリケーション層の並列処理数 | Web/APプロセスの数。過負荷やプロセス枯渇を検知。 |
| healthCheck | 死活監視・応答遅延 | アプリが応答しなくなる兆候を早期検知。 |
DBサーバーで重視すべき項目と見るべき観点
| 項目名 | 評価観点 | 説明 |
|---|
| CPU utilization / CPU load | クエリ処理負荷 | 複雑なSQLやJOIN処理でCPUが逼迫しないか確認。 |
| Memory usage | キャッシュヒット率への影響 | メモリ不足でディスクアクセスが増えると性能劣化。 |
| Swap usage | メモリ設計の問題検知 | スワップが発生していれば要注意(設定再検討)。 |
| Disk I/O(特にDB格納先) | 読み書き負荷 | 高I/Oは遅延やロック、書き込み待ちなどの要因に。 |
| Disk space usage | 空き容量 | INSERTが増える性能テスト中は注意(特に / や /var/lib/pgsql)。 |
| Network traffic(eth0など) | AP⇔DBの通信量 | クエリ件数、データ量に比例。急増していればAP負荷に連動。 |
| healthCheck | DB死活監視 | 応答不能や重度遅延を早期発見。 |
性能テストでのチェックポイント
性能テストではリソース監視とテストツールの応答時間の関係を見ることが極めて重要です。
以下のような流れで活用します。
- スループットや応答時間のグラフとZabbixのリソース使用率を並べて可視化
- 応答時間が劣化し始めたタイミングで、どのリソースがボトルネックか特定
- 特定の項目(CPU, I/O, DB接続など)に閾値超過がないかを重点的に確認
ボトルネック発見の具体例
- 応答時間の上昇とともに
system.cpu.util[,user] が80%以上 → アプリ処理のCPU負荷が高い
- スループットが落ちて
system.cpu.util[,iowait] が高い → I/O待ちでスレッドが詰まっている
pgsql.connections が閾値に近づいている → コネクション枯渇で応答が遅延
| チェック内容 | 評価方法 |
|---|
| 同時接続・負荷時に CPUが飽和していないか | CPU load がコア数の2倍以上で継続しているとNG |
| スワップ使用 が発生していないか | Memory usageとSwap usageをセットで監視 |
| ディスクI/O が急激に上がっていないか | 書き込み待ち・遅延を生む要因、特にDB側で重要 |
| ネットワーク帯域 を使い切っていないか | traffic on eth0/bond0 がピークで100%に近くないか |
| healthCheckが失敗していないか | HTTP 5xxやDB接続エラーを確認(リクエスト失敗と連動) |
サーバー別の監視ポイント要約
| サーバー | 優先監視項目 | 補足 |
|---|
| APサーバー | CPU, Memory, Swap, Network, HTTPプロセス | 同時リクエスト数・スレッド管理が鍵 |
| DBサーバー | Disk I/O, Memory, CPU, Network, Swap | 読み書き性能とキャッシュ戦略が鍵 |
以下はグラフで監視する際のイメージです。
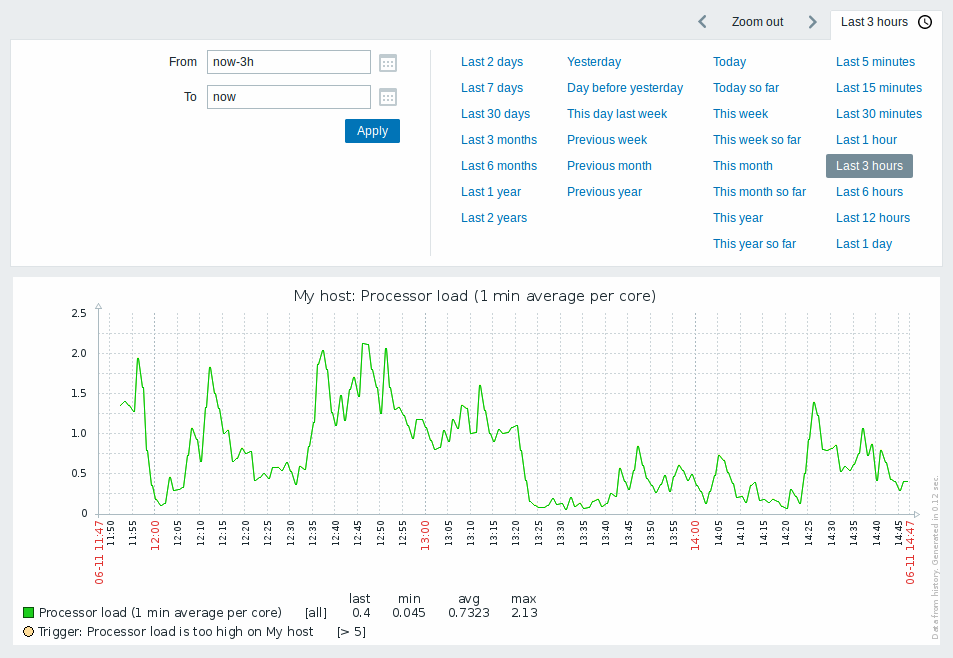
まとめ
Zabbixによるリソース監視は、システム全体の健康状態を時系列で可視化できるのが大きな利点です。
性能テスト時だけでなく、運用中の**「変化の兆候」に気づく体制を作ることが安定運用への第一歩**です。
- 監視すべき項目は目的や役割によって変わる(APサーバーとDBサーバーで注目点が異なる)
- 複数指標を相関的に見ることでボトルネックの特定がしやすくなる
- 閾値の定義と通知設定も重要(例:CPU 80%以上でアラート)
参考
Zabbix マニュアル



コメント